Grafana 대시보드 설정하기
이제 노드가 실행 중이므로, 노드가 올바르게 작동하는지(그리고 어떤 수익을 창출하고 있는지) 한눈에 모니터링할 수 있는 편리한 방법이 필요할 것입니다.
이 작업을 수행하는 도구가 많이 있습니다.
가장 인기 있는 도구 중 하나는 Grafana입니다. 브라우저로 액세스할 수 있는 사용하기 쉬운 범용 대시보드 시스템입니다.
Rocket Pool은 Grafana와 그 종속성을 기본적으로 지원합니다. 각 Consensus 클라이언트에 대해 미리 구축된 대시보드도 함께 제공됩니다.
예를 들어, Hoodi 테스트 네트워크에서 대시보드가 어떻게 보이는지 스냅샷입니다:
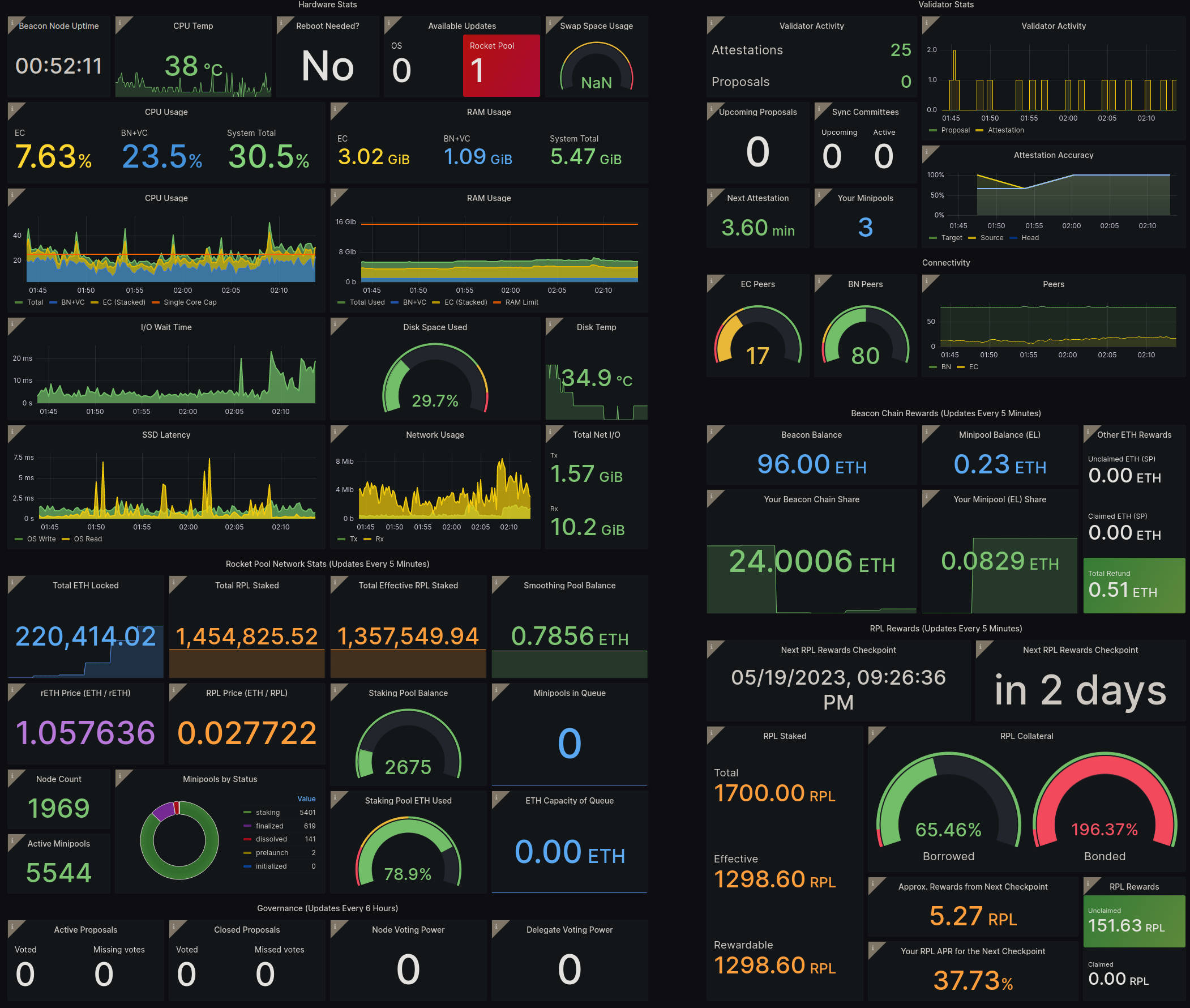
표준 대시보드에는 편리한 형식으로 다음 정보가 포함됩니다:
- 왼쪽 상단: 머신의 상태 및 성능에 대한 중요한 통계와 보류 중인 시스템 업데이트
- 오른쪽 상단: Beacon Chain의 검증자 활동 및 성능, Execution 및 Consensus 클라이언트 통계
- 왼쪽 하단: 참조용 전체 Rocket Pool 네트워크에 대한 세부 정보
- 오른쪽 하단: ETH 및 RPL 스테이킹 보상에 대한 세부 정보
이 가이드에서는 Rocket Pool의 메트릭 시스템을 활성화하여 이 대시보드를 사용하거나 직접 대시보드를 만드는 방법을 보여드립니다!
Rocket Pool 메트릭 스택 개요
Smartnode 구성 과정에서 메트릭을 활성화하도록 선택하면 노드에 다음 프로세스가 추가됩니다:
- Prometheus - 위에서 본 모든 메트릭(및 더 많은 메트릭)을 수집, 저장 및 보고하는 데이터 수집, 저장 및 보고 시스템으로, 시간 경과에 따라 볼 수 있도록 저장합니다
- Prometheus Node Exporter - 머신의 상태 정보(CPU 사용량, RAM 사용량, 여유 디스크 공간 및 스왑 공간 등)를 수집하여 Prometheus에 보고하는 서비스
- Grafana, 노드에서 호스팅되는 편리한 웹사이트를 통해 Prometheus의 데이터를 노출하는 도구
- 사용 가능한 운영 체제 업데이트를 Prometheus에 보고하는 선택적 사용자 지정 스크립트 세트로, 시스템을 패치해야 하는지 알 수 있습니다
기본 구성은 Smartnode의 나머지 Docker 컨테이너와 함께 이러한 모든 서비스가 포함된 Docker 컨테이너를 생성합니다.
Grafana용 노드 머신에 포트를 열어 로컬 네트워크의 모든 머신에서 브라우저로 대시보드에 액세스할 수 있습니다.
메트릭 서버 활성화
Docker 모드에서 메트릭을 활성화하는 것이 가장 쉽습니다.
Smartnode 구성 명령을 다시 실행하여 시작합니다:
rocketpool service config
Monitoring / Metrics 섹션으로 이동하여 Enable Metrics 체크박스를 선택합니다.
포트 설정을 세밀하게 조정하려는 경우 여기에서 수행할 수 있습니다.
이러한 모든 포트는 Grafana 포트를 제외하고 Docker의 내부 네트워크로 제한됩니다. Grafana 포트는 머신에서 열리므로(데스크톱이나 휴대폰과 같은 다른 머신에서 브라우저를 통해 액세스할 수 있도록) 기본 포트가 이미 있는 것과 충돌하는 경우 변경할 수 있습니다.
저장하고 종료하면 smartnode가 Prometheus, Node Exporter 및 Grafana Docker 컨테이너를 시작합니다.
또한 Consensus 및 Validator 클라이언트를 수정하여 자체 메트릭을 Prometheus에 노출합니다.
운영 체제 및 Rocket Pool 업데이트 추적기는 최대 유연성을 위해 기본적으로 설치되지 않지만 프로세스는 간단합니다.
대시보드에 시스템에 사용 가능한 업데이트 수를 표시하도록 설치하려면 다음 명령을 사용할 수 있습니다:
rocketpool service install-update-tracker
내부적으로 이것은 운영 체제의 패키지 관리자에 연결하고 주기적으로 업데이트를 확인하고 해당 정보를 Prometheus에 보내는 서비스를 설치합니다.
이 서비스는 모든 운영 체제마다 다르지만 다음에서 작동하는 것으로 확인되었습니다:
- Ubuntu 20.04+
- Debian 9 and 10
- CentOS 7 and 8
- Fedora 34
참고
서비스를 자동으로 활성화하는 것은 SELinux와 호환되지 않습니다.
시스템에 SELinux가 기본적으로 활성화된 경우(CentOS 및 Fedora의 경우) 설치 명령은 _대부분의 작업을 완료_하지만 마지막에 프로세스를 수동으로 완료하는 방법에 대한 지침도 제공합니다.
이 검사 중에 설치된 Rocket Pool Smartnode 버전을 최신 릴리스와 비교하고 새 릴리스가 있으면 알려줍니다.
업데이트 추적기를 활성화한 경우 마지막 단계는 다음 명령으로 Node Exporter를 다시 시작하는 것입니다:
docker restart rocketpool_exporter
그 후에는 모든 설정이 완료됩니다.
Hybrid 모드는 Docker 모드와 유사하게 작동합니다. 유일한 차이점은 메트릭 활성화를 위한 적절한 명령줄 플래그를 Execution 및 Consensus Client 서비스 정의에 수동으로 추가해야 한다는 것입니다.
먼저 Execution Client를 업데이트합니다.
Execution Client를 설치할 때 생성한 systemd 유닛 파일을 열고 실행 중인 클라이언트에 따라 올바른 플래그가 있는지 확인합니다:
--metrics --metrics.addr 0.0.0.0 --metrics.port 9105
--Metrics.Enabled true --Metrics.ExposePort 9105
--metrics-enabled --metrics-host=0.0.0.0 --metrics-port=9105
다음으로 Consensus Client를 업데이트합니다.
Consensus Client를 설치할 때 생성한 systemd 유닛 파일을 열고 실행 중인 클라이언트에 따라 올바른 플래그가 있는지 확인합니다:
--metrics --metrics-address 0.0.0.0 --metrics-port 9100 --validator-monitor-auto
--metrics --metrics.address 0.0.0.0 --metrics.port 9100
--metrics --metrics-address=0.0.0.0 --metrics-port=9100
--monitoring-host 0.0.0.0 --monitoring-port 9100
--disable-monitoring 플래그가 표시되면 제거합니다.
--metrics-enabled=true --metrics-interface=0.0.0.0 --metrics-port=9100 --metrics-host-allowlist=*
이미 이러한 플래그가 설정되어 있고 솔로 검증자 모니터링을 위해 다른 포트를 사용하는 경우 그대로 두고 사용 중인 포트를 기록해 둡니다.
이제 위로 스크롤하여 이 섹션의 Docker 탭에 있는 지침을 따라 프로세스를 완료합니다. rocketpool service config를 실행할 때 나열된 포트를 사용하는 사용자 지정 포트로 대체해야 한다는 점을 명심하세요.
Grafana와 Prometheus의 Native 설치는 고급 사용자에게만 권장됩니다. systemd, 파일 권한, 사용자 및 네트워크 관리와 같은 Linux 관리 기술이 필요합니다.
먼저 Execution Client 및 Consensus Client에서 메트릭이 활성화되어 있는지 확인합니다. 자세한 내용은 'Hybrid' 탭을 참조하세요.
다음으로 공식 다운로드 페이지에서 미리 빌드된 prometheus 및 node_exporter 패키지를 확인합니다.
플랫폼에 적합한 아키텍처(amd64 또는 arm64)를 가진 패키지를 선택합니다.
가장 최신 LTS(Long Time Support) 버전의 Prometheus를 권장합니다.
예를 들어 wget을 사용하여 Linux amd64용 prometheus v2.45.3 LTS 및 node_exporter v1.7.0을 다운로드하려면 다음을 수행합니다:
wget https://github.com/prometheus/prometheus/releases/download/v2.45.3/prometheus-2.45.3.linux-amd64.tar.gz
wget https://github.com/prometheus/node_exporter/releases/download/v1.7.0/node_exporter-1.7.0.linux-amd64.tar.gz
wget https://github.com/prometheus/alertmanager/releases/download/v0.26.0/alertmanager-0.26.0.linux-amd64.tar.gz
다운로드한 아카이브에서 prometheus 및 node_exporter 실행 파일을 추출합니다.
sudo tar -zxvf prometheus-2.45.3.linux-amd64.tar.gz -C /usr/local/bin --wildcards '*/prometheus' --strip-components=1
sudo tar -zxvf node_exporter-1.7.0.linux-amd64.tar.gz -C /usr/local/bin --wildcards '*/node_exporter' --strip-components=1
sudo tar -zxvf alertmanager-0.26.0.linux-amd64.tar.gz -C /usr/local/bin --wildcards '*/alertmanager' --strip-components=1
prometheus 및 alertmanager 구성을 위한 디렉토리를 만듭니다.
sudo mkdir /etc/prometheus
sudo mkdir /etc/alertmanager
sudo mkdir /var/lib/prometheus
sudo mkdir /var/lib/alertmanager
다음 내용으로 /etc/prometheus/prometheus.yml 파일을 만듭니다:
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
scrape_timeout: 12s # Timeout must be shorter than the interval
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9091"]
- job_name: "node"
static_configs:
- targets: ["localhost:9103"]
# - targets: ['localhost:9103', 'node_hostname:9103']
- job_name: "eth1"
static_configs:
- targets: ["localhost:9105"]
# Uncomment the line below if you are using geth as Execution Client
#metrics_path: /debug/metrics/prometheus
- job_name: "eth2"
static_configs:
- targets: ["localhost:9100"]
- job_name: "validator"
static_configs:
- targets: ["validator:9101"]
- job_name: "rocketpool"
scrape_interval: 5m
scrape_timeout: 5m
static_configs:
- targets: ["node:9102"]
- job_name: "watchtower"
scrape_interval: 5m
scrape_timeout: 5m
static_configs:
- targets: ["watchtower:9104"]
alerting:
alertmanagers:
- static_configs:
- targets: ["localhost:9093"]
참고
필요한 경우 Execution Client 및 Consensus Client의 포트 번호를 변경합니다.
prometheus를 실행하는 호스트와 다른 호스트에서 노드를 실행하고 있을 수 있습니다. 이 경우
rocketpool 노드 호스트에 node_exporter를 설치하고 모니터링하려는 모든 머신을 포함하도록 node 작업의 targets을 업데이트합니다.
또한 Execution Client가 geth인 경우 metrics_path를 조정합니다. geth는 메트릭에 대한 비표준 엔드포인트를 노출합니다.
다음 내용으로 /etc/alertmanager/alertmanager.yml을 만듭니다:
global:
# ResolveTimeout is the default value used by alertmanager if the alert does
# not include EndsAt, after this time passes it can declare the alert as resolved if it has not been updated.
# This has no impact on alerts from Prometheus, as they always include EndsAt.
# default = 5m
resolve_timeout: 5m
route:
# The labels by which incoming alerts are grouped together.
group_by: ["alertname"]
# How long to initially wait to send a notification for a group
# of alerts. Allows to wait for an inhibiting alert to arrive or collect
# more initial alerts for the same group.
group_wait: 30s
# How long to wait before sending a notification about new alerts that
# are added to a group of alerts for which an initial notification has
# already been sent. (Usually ~5m or more.)
group_interval: 5m
# How long to wait before sending a notification again if it has already been sent successfully for an alert.
repeat_interval: 4h
routes:
# severity=info: Don't send the follow-up resolved notification.
- match:
severity: info
continue: false
# The notification destination
receiver: "node_operator_no_resolved"
# all other alerts get sent notifications for the initial firing _and_ resolved notifications.
- receiver: "node_operator_default"
#match: We want this to match all alerts (severity=info is first though so it will stop)
# The notification destination
receiver: "node_operator_default"
receivers:
- name: "node_operator_default"
discord_configs:
- webhook_url: "https://discord.com/api/webhooks/1206697259694170212/_Pk1eVVgXFLdwU1k0rfwehSvNLiAQJytVV_Ze8QYOhupHnhiB5c8awPBTfuw41lN9GJk"
- name: "node_operator_no_resolved"
discord_configs:
- webhook_url: "https://discord.com/api/webhooks/1206697259694170212/_Pk1eVVgXFLdwU1k0rfwehSvNLiAQJytVV_Ze8QYOhupHnhiB5c8awPBTfuw41lN9GJk"
send_resolved: false
inhibit_rules:
# Inhibit rules mute a new alert (target) that matches an existing alert (source).
- source_match:
# if the existing alert (source) is severity=critical
severity: "critical"
target_match:
# and the new alert (target) is severity=warning
severity: "warning"
# and the alertname, job, and instance labels have the same value
equal: ["alertname", "job", "instance"]
prometheus 및 alertmanager를 위한 시스템 사용자를 만듭니다.
sudo useradd -r -s /sbin/nologin prometheus
sudo useradd -r -s /sbin/nologin alertmanager
prometheus/alertmanager 파일 소유권 및 권한을 변경합니다.
sudo chown prometheus:prometheus /usr/local/bin/prometheus
sudo chown alertmanager:alertmanager /usr/local/bin/alertmanager
sudo chown prometheus:prometheus /usr/local/bin/node_exporter
sudo chown -R prometheus:prometheus /etc/prometheus
sudo chown -R alertmanager:alertmanager /etc/alertmanager
sudo chown -R prometheus:prometheus /var/lib/prometheus
sudo chown -R alertmanager:alertmanager /var/lib/alertmanager
sudo chmod u+sx,g+sx,o-wx /usr/local/bin/prometheus
sudo chmod u+sx,g+sx,o-wx /usr/local/bin/alertmanager
sudo chmod u+sx,g+sx,o-wx /usr/local/bin/node_exporter
node_exporter 서비스 구성을 위한 /lib/systemd/system/node-exporter.service 파일을 만듭니다.
[Unit]
Description=Node metrics exporter for Prometheus
Documentation=https://prometheus.io/docs/introduction/overview
Wants=network-online.target
After=network-online.target
[Service]
User=prometheus
Group=prometheus
Type=simple
Restart=on-failure
WorkingDirectory=/var/lib/prometheus
RuntimeDirectory=node-exporter
RuntimeDirectoryMode=0750
ExecStart=/usr/local/bin/node_exporter --web.listen-address=:9103
[Install]
WantedBy=multi-user.target
참고
node_exporter가 실행되는 포트를 변경하려면
ExecStart 매개변수의 명령을 수정합니다. 기본 포트는 9100입니다.
prometheus 서비스 구성을 위한 /lib/systemd/system/prometheus.service 파일을 만듭니다.
[Unit]
Description=Prometheus instance
Documentation=https://prometheus.io/docs/introduction/overview
Wants=network-online.target
After=network-online.target
[Service]
User=prometheus
Group=prometheus
Type=simple
Restart=on-failure
WorkingDirectory=/var/lib/prometheus
RuntimeDirectory=prometheus
RuntimeDirectoryMode=0750
ExecStart=/usr/local/bin/prometheus --config.file /etc/prometheus/prometheus.yml --web.listen-address=:9091
[Install]
WantedBy=multi-user.target
참고
prometheus가 실행되는 포트를 변경하려면
ExecStart 매개변수의 명령을 수정합니다. 기본 포트는 9090입니다.
alertmanager 서비스 구성을 위한 /lib/systemd/system/alertmanager.service 파일을 만듭니다.
[Unit]
Description=Alertmanager instance
Documentation=https://prometheus.io/docs/alerting/latest/alertmanager/
Wants=network-online.target
After=network-online.target
[Service]
User=alertmanager
Group=alertmanager
Type=simple
Restart=on-failure
WorkingDirectory=/var/lib/alertmanager
RuntimeDirectory=alertmanager
RuntimeDirectoryMode=0750
ExecStart=/usr/local/bin/alertmanager --config.file /etc/alertmanager/alertmanager.yml --web.listen-address=:9093
[Install]
WantedBy=multi-user.target
참고
alertmanager가 실행되는 포트를 변경하려면
ExecStart 매개변수의 명령을 수정합니다. 기본 포트는 9093입니다.
systemd가 새 서비스를 인식하도록 합니다.
sudo systemctl daemon-reload
node-exporter 서비스를 활성화하고 시작합니다.
sudo systemctl enable node-exporter
sudo systemctl start node-exporter
서비스가 실행 중인지 확인하기 위해 서비스 상태를 확인합니다.
sudo systemctl status node-exporter
prometheus 서비스를 활성화하고 시작합니다.
sudo systemctl enable prometheus
sudo systemctl start prometheus
alertmanager 서비스를 활성화하고 시작합니다.
sudo systemctl enable alertmanager
sudo systemctl start alertmanager
서비스가 실행 중인지 확인하기 위해 서비스 상태를 확인합니다.
sudo systemctl status prometheus
sudo systemctl status alertmanager
Grafana를 위한 패키지 저장소를 설정합니다.
sudo apt-get update
sudo apt-get install -y apt-transport-https software-properties-common
sudo mkdir -p /etc/apt/keyrings/
wget -q -O - https://apt.grafana.com/gpg.key | gpg --dearmor | sudo tee /etc/apt/keyrings/grafana.gpg > /dev/null
echo "deb [signed-by=/etc/apt/keyrings/grafana.gpg] https://apt.grafana.com stable main" | sudo tee -a /etc/apt/sources.list.d/grafana.list
Grafana를 설치합니다.
sudo apt-get update
sudo apt-get install grafana
/etc/grafana/grafana.ini에서 설정을 확인합니다. 이 문서의 다른 섹션과 일치하도록 http_port를 3100으로 변경합니다.
Grafana에서 Prometheus의 메트릭을 시각화하도록 데이터 소스를 구성합니다. /etc/grafana/provisioning/datasources/prometheus.yml 파일을 만듭니다.
apiVersion: 1
deleteDatasources:
- name: Prometheus
orgId: 1
datasources:
- name: Prometheus
type: prometheus
access: proxy
orgId: 1
url: http://localhost:9091
basicAuth: false
isDefault: true
version: 1
editable: true
참고
Prometheus 수신 포트를 변경한 경우
url을 편집합니다.
Grafana를 위한 서비스를 활성화하고 시작합니다.
sudo systemctl daemon-reload
sudo systemctl enable grafana-server
sudo systemctl start grafana-server
Grafana가 실행 중인지 확인합니다.
sudo systemctl status grafana-server
이것이 거의 전부입니다.
모니터링을 위한 연결을 허용하도록 방화벽 구성
참고
노드 보안 섹션에서 참조된 대로 UFW가 활성화된 경우 Prometheus와 Execution/Consensus Client 간의 로컬 연결을 허용하기 위해 몇 개의 포트를 열어야 합니다. 아래 단계를 따르세요.
다음을 실행하고 필요에 따라 포트를 교체합니다:
RP_NET=$(docker inspect rocketpool_net | grep -Po "(?<=\"Subnet\": \")[0-9./]+")
sudo ufw allow from $RP_NET to any port 9105 comment "Allow Prometheus access to Execution Client"
sudo ufw allow from $RP_NET to any port 9100 comment "Allow Prometheus access to Consensus Client"
sudo ufw allow from $RP_NET to any port 9103 comment "Allow Prometheus access to Exporter"
RocketPool 노드와 Prometheus가 다른 호스트에 있는 경우 노드 호스트의 방화벽을 구성하여 Prometheus 호스트 IP에서 노드 모니터링 포트로의 들어오는 트래픽을 허용해야 합니다.
또한 Prometheus 머신에서 UFW를 구성하여 Prometheus 호스트에서 RocketPool 노드 호스트로의 나가는 트래픽을 허용해야 합니다.
노드 호스트 IP가 192.168.1.5이고 Prometheus 호스트 IP가 192.168.1.6인 경우 노드에 대한 UFW 규칙은 다음과 같습니다:
sudo ufw allow from 192.168.1.6 to any port 9100:9105 proto tcp comment 'Allow Prometheus host to scrape metrics of this host'
Prometheus 호스트의 경우:
sudo ufw allow out from any to 192.168.1.5 port 9100:9105 proto tcp comment 'Allow this host to scrape node metrics'
Grafana 수신 포트가 3100이라고 가정하고 네트워크에서 Grafana를 노출하는 방법을 계속 읽어보세요.
그런 다음 방화벽을 열어 외부 장치가 Grafana 대시보드에 액세스할 수 있도록 할 수 있습니다.
로컬 네트워크 내의 모든 머신에서 Grafana에 액세스하고 다른 곳에서의 액세스를 거부하려면 이것을 사용하세요.
이것이 가장 일반적인 사용 사례입니다.
먼저 로컬 네트워크가 192.168.1.xxx 구조를 사용하는지 확인하세요.
로컬 네트워크가 다른 주소 구조(예: 192.168.99.xxx)를 사용하는 경우 아래 명령을 로컬 네트워크의 구성과 일치하도록 변경해야 할 수 있습니다.
# This assumes your local IP structure is 192.168.1.xxx
sudo ufw allow from 192.168.1.0/24 proto tcp to any port 3100 comment 'Allow grafana from local network'
Rocket Pool 노드가 Grafana를 보는 장치와 동일한 서브넷에 연결되어 있지 않은 경우 이것을 사용하세요. 이는 노드가 ISP의 모뎀에 직접 연결되어 있고 Grafana를 보는 데 사용하는 장치가 보조 라우터에 연결되어 있을 때 발생할 수 있습니다.
먼저 로컬 네트워크가 192.168.1.xxx 구조를 사용하는지 확인하세요.
로컬 네트워크가 다른 주소 구조(예: 192.168.99.xxx)를 사용하는 경우 아래 명령을 로컬 네트워크의 구성과 일치하도록 변경해야 할 수 있습니다.
# To allow any devices in the broader subnet
# for example allowing 192.168.2.20 to access
# grafana on 192.168.1.20
sudo ufw allow from 192.168.1.0/16 proto tcp to any port 3100 comment 'Allow grafana from local subnets'
이것은 어디서나 Grafana에 액세스할 수 있게 합니다.
로컬 네트워크 외부에서 액세스하려면 여전히 라우터 설정에서 Grafana 포트(기본 3100)를 포워딩해야 합니다.
# Allow any IP to connect to Grafana
sudo ufw allow 3100/tcp comment 'Allow grafana from anywhere'
Grafana 설정
이제 메트릭 서버가 준비되었으므로 로컬 네트워크의 모든 브라우저로 액세스할 수 있습니다.
Smartnode 설치 모드에 대한 아래 탭을 참조하세요.
다음 URL로 이동하고 필요에 따라 설정으로 변수를 대체합니다:
http://<your node IP>:<grafana port>
예를 들어 노드의 IP가 192.168.1.5이고 기본 Grafana 포트인 3100을 사용한 경우 브라우저에서 다음 URL로 이동합니다:
다음과 같은 로그인 화면이 표시됩니다:

기본 Grafana 정보는 다음과 같습니다:
Username: admin
Password: admin
그런 다음 admin 계정의 기본 비밀번호를 변경하라는 메시지가 표시됩니다.
강력한 비밀번호를 선택하고 잊지 마세요!
팁
관리자 비밀번호를 잃어버린 경우 노드에서 다음 명령을 사용하여 재설정할 수 있습니다:
docker exec -it rocketpool_grafana grafana-cli admin reset-admin-password admin
sudo grafana-cli admin reset-admin-password admin
기본 admin 자격 증명을 사용하여 다시 Grafana에 로그인할 수 있으며 admin 계정의 비밀번호를 변경하라는 메시지가 표시됩니다.
커뮤니티 멤버 tedsteen의 작업 덕분에 Grafana가 자동으로 Prometheus 인스턴스에 연결되어 수집하는 메트릭에 액세스할 수 있습니다.
대시보드를 가져오기만 하면 됩니다!
Rocket Pool 대시보드 가져오기
이제 Grafana가 Prometheus에 연결되었으므로 표준 대시보드를 가져올 수 있습니다(또는 해당 프로세스에 익숙한 경우 제공하는 메트릭을 사용하여 직접 대시보드를 만들 수 있습니다).
Create 메뉴(오른쪽 사이드바의 더하기 아이콘)로 이동하여 Import를 클릭하여 시작합니다:
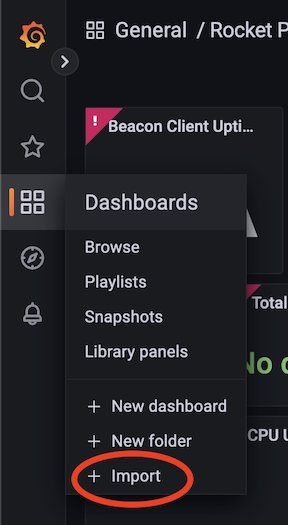
Import via grafana.com 상자에서 대시보드 ID를 입력하라는 메시지가 표시되면 21863을 입력하거나 전체 URL((https://grafana.com/grafana/dashboards/24900-rocket-pool-dashboard-v1-4-0/)을 사용하고 Load 버튼을 누릅니다.
여기에서 대시보드의 이름 및 저장 위치(많은 대시보드를 사용하고 정리하려는 경우가 아니면 기본 General 폴더가 괜찮습니다)와 같은 대시보드에 대한 일부 정보가 표시됩니다.
하단의 Prometheus 드롭다운에서 **Prometheus (default)**라는 레이블이 지정된 단일 옵션만 있어야 합니다.
이 옵션을 선택합니다.
화면은 다음과 같아야 합니다:
일치하는 경우 Import 버튼을 클릭하면 즉시 새 대시보드로 이동합니다.
첫눈에 노드와 검증자에 대한 많은 정보를 볼 수 있습니다.
각 상자에는 왼쪽 상단 모서리에 유용한 툴팁(i 아이콘)이 있어 마우스를 올리면 자세한 내용을 알 수 있습니다.
예를 들어 Your Validator Share 상자의 툴팁은 다음과 같습니다:
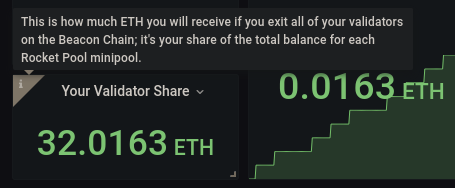
그러나 아직 설정이 완료되지 않았습니다. 아직 조금 더 구성할 것이 있습니다.
참고
일부 상자(특히 APR 상자)는 Shapella가 스키밍된 보상을 제공하는 방식으로 인해 일시적으로 비활성화되었습니다.
역사적 보상을 올바르게 추적할 수 있는 Smartnode의 향후 버전에서 다시 활성화됩니다.
시스템에 맞게 하드웨어 모니터 조정
이제 대시보드가 작동하지만 SSD Latency 및 Network Usage와 같은 일부 상자가 비어 있을 수 있습니다.
이러한 항목을 캡처하는 방법을 알 수 있도록 대시보드를 특정 하드웨어에 맞게 조정해야 합니다.
CPU Temp
CPU 온도 게이지를 업데이트하려면 CPU Temp 상자의 제목을 클릭하고 드롭다운에서 Edit를 선택합니다.
이제 화면은 다음과 같습니다:
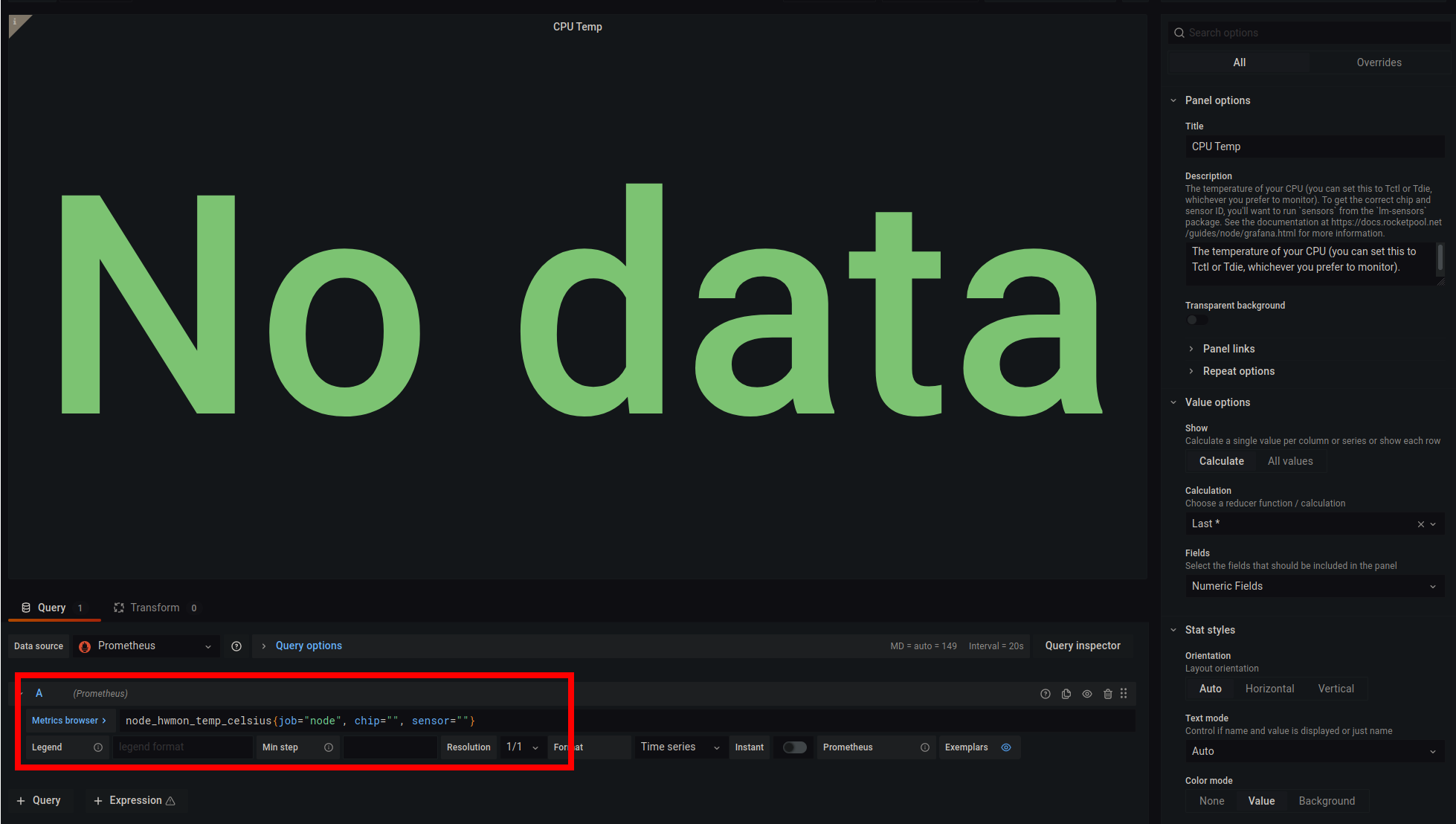
이것은 Grafana의 편집 모드로, 표시되는 내용과 모양을 변경할 수 있습니다.
우리는 Metrics browser 버튼 오른쪽의 빨간색으로 강조 표시된 쿼리 상자에 관심이 있습니다.
기본적으로 해당 상자에는 다음이 있습니다:
node_hwmon_temp_celsius{job="node", chip="", sensor=""}
이 텍스트에는 현재 비어 있는 두 개의 필드가 있습니다: chip 및 sensor.
이들은 각 머신에 고유하므로 머신이 제공하는 것에 따라 채워야 합니다.
이렇게 하려면 다음 단계를 따르세요:
, sensor="" 부분을 제거하여 chip=""}로 끝나도록 합니다. 명확성을 위해 전체는 이제 node_hwmon_temp_celsius{job="node", chip=""}가 되어야 합니다.- 커서를
chip=""의 따옴표 사이에 놓고 Ctrl+Spacebar를 누릅니다. 그러면 사용 가능한 옵션이 있는 자동 완성 상자가 나타납니다. 다음과 같습니다:
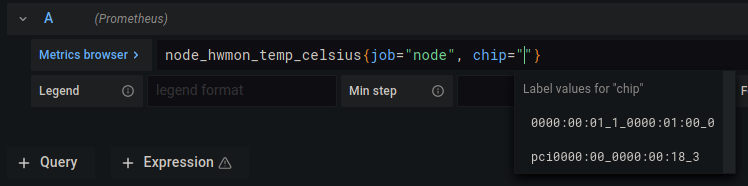
- 시스템의 CPU에 해당하는 옵션을 선택합니다.
- 선택한 후
, sensor=""를 문자열에 다시 추가합니다. 커서를 sensor=""의 따옴표 사이에 놓고 Ctrl+Spacebar를 눌러 다른 자동 완성 메뉴를 표시합니다. 모니터링할 센서를 선택합니다.
팁
어떤 chip 또는 sensor가 올바른지 모르는 경우 올바른 것을 찾을 때까지 모두 시도해야 합니다. 이를 돕기 위해 lm-sensors 패키지를 설치하고(예: Debian/Ubuntu에서 sudo apt install lm-sensors) sensors -u 명령을 실행하여 컴퓨터에 있는 센서를 제공합니다. 이름과 ID를 기반으로 Grafana 목록의 칩 ID를 여기에서 보이는 것과 연관시킬 수 있습니다.
예를 들어 sensors -u 명령의 출력 중 하나는 다음과 같습니다:
k10temp-pci-00c3
Tctl:
temp1_input: 33.500
Tdie:
temp2_input: 33.500
우리의 경우 Grafana의 해당 칩은 pci0000:00_0000:00:18_3이고 해당 센서는 temp1입니다.
선택에 만족하면 화면 오른쪽 상단의 파란색 Apply 버튼을 클릭하여 설정을 저장합니다.
참고
모든 시스템이 CPU 온도 정보를 노출하는 것은 아닙니다. 특히 가상 머신이나 클라우드 기반 시스템이 그렇습니다.
chip에 대한 자동 완성 필드에 아무것도 없으면 이것이 아마도 해당 경우이며 CPU 온도를 모니터링할 수 없습니다.
SSD Latency
SSD Latency 차트는 읽기/쓰기 작업이 수행되는 데 걸리는 시간을 추적합니다.
이는 SSD가 얼마나 빠른지 측정하는 데 유용하므로 검증자가 성능 저하를 겪을 때 병목 현상이 되는지 알 수 있습니다.
차트에서 추적할 SSD를 업데이트하려면 SSD Latency 제목을 클릭하고 Edit를 선택합니다.
이 차트에는 총 8개의 device="" 부분이 있는 네 개의 쿼리 필드(네 개의 텍스트 상자)가 있습니다.
이 부분의 처음 네 개를 추적하려는 장치로 업데이트해야 합니다.
커서를 따옴표 사이에 놓고 Ctrl+Spacebar를 눌러 Grafana의 자동 완성 목록을 표시하고 각 device="" 부분에 대해 올바른 옵션을 선택합니다.
가장 왼쪽의 빈 설정부터 시작해야 합니다. 그렇지 않으면 자동 완성 목록이 나타나지 않을 수 있습니다.
팁
추적할 장치를 모르는 경우 다음 명령을 실행합니다:
그러면 장치 및 파티션 목록을 보여주는 트리가 출력됩니다. 예를 들어:
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
...
loop25 7:25 0 132K 1 loop /snap/gtk2-common-themes/9
loop26 7:26 0 65,1M 1 loop /snap/gtk-common-themes/1515
nvme0n1 259:0 0 238,5G 0 disk
├─nvme0n1p1 259:1 0 512M 0 part /boot/efi
├─nvme0n1p2 259:2 0 150,1G 0 part /
├─nvme0n1p3 259:3 0 87,4G 0 part
└─nvme0n1p4 259:4 0 527M 0 part
Smartnode 설치 중에 Docker의 기본 위치를 다른 드라이브로 변경하지 않은 경우 추적하려는 디스크는 운영 체제가 설치된 디스크입니다.
MOUNTPOINT 열에서 단순히 /로 레이블이 지정된 항목을 찾은 다음 해당 항목을 상위 장치(TYPE 열에 disk가 있는 항목)로 다시 따라갑니다.
일반적으로 SATA 드라이브의 경우 sda, NVMe 드라이브의 경우 nvme0n1입니다.
Docker의 기본 위치를 다른 드라이브로 변경했거나 하이브리드/네이티브 설정을 실행하는 경우 "마운트 포인트를 따라가는" 동일한 기술을 사용하여 체인 데이터가 있는 장치를 결정할 수 있어야 합니다.
선택적으로 시스템의 두 번째 디스크의 지연 시간도 추적할 수 있습니다.
이것은 운영 체제와 체인 데이터를 별도의 드라이브에 보관하는 사람들을 위한 것입니다.
이를 설정하려면 마지막 두 쿼리 필드에 대해 위의 지침을 따르고 device="" 부분 값을 추적하려는 디스크의 값으로 대체합니다.
선택에 만족하면 화면 오른쪽 상단의 파란색 Apply 버튼을 클릭하여 설정을 저장합니다.
Network Usage
이 차트는 특정 네트워크 연결을 통해 보내고 받는 데이터의 양을 추적합니다.
예상대로 대시보드는 추적할 네트워크를 알아야 합니다.
변경하려면 Network Usage 제목을 클릭하고 Edit를 선택합니다.
이 차트에는 총 두 개의 device="" 부분이 있는 두 개의 쿼리 필드가 있습니다.
이것을 추적하려는 네트워크로 업데이트해야 합니다.
커서를 따옴표 사이에 놓고 Ctrl+Spacebar를 눌러 Grafana의 자동 완성 목록을 표시하고 각 device="" 부분에 대해 올바른 옵션을 선택합니다.
팁
추적할 장치를 모르는 경우 다음 명령을 실행합니다:
출력은 다음과 같습니다:
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
default 192.168.1.1 0.0.0.0 UG 100 0 0 eth0
192.168.1.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
192.168.1.1 0.0.0.0 255.255.255.255 UH 100 0 0 eth0
Destination 열에서 default 값이 있는 행을 찾습니다.
해당 행을 Iface 열까지 따라갑니다.
여기에 나열된 장치가 사용하려는 장치입니다. 이 예에서는 eth0입니다.
선택에 만족하면 화면 오른쪽 상단의 파란색 Apply 버튼을 클릭하여 설정을 저장합니다.
Total Net I/O
이것은 보내고 받은 총 데이터 양을 추적합니다.
예를 들어 ISP가 한 달에 특정 양의 데이터로 제한하는 경우 유용할 수 있습니다.
설정은 위의 Network Usage 상자와 동일하므로 이 상자에 대해서도 해당 지침을 따르세요.
Disk Space Used
이것은 운영 체제 디스크가 얼마나 가득 차는지 추적하므로 정리할 때(그리고 체인 데이터가 동일한 드라이브에 있는 경우 Geth 또는 Nethermind를 프루닝할 때)를 알 수 있습니다.
단계는 위의 SSD Latency 상자와 동일하므로 이 상자에 대해서도 해당 지침을 따르세요.
참고로 MOUNTPOINT 열에 /가 있는 파티션을 포함하는 드라이브를 원합니다. 이것이 운영 체제 드라이브이기 때문입니다.
첫 번째 쿼리 필드에 이것을 채웁니다.
선택적으로 시스템의 두 번째 디스크의 여유 공간도 추적할 수 있습니다.
이것은 운영 체제와 체인 데이터를 별도의 드라이브에 보관하는 사람들을 위한 것입니다.
동일한 프로세스를 따라 설정하되 MOUNTPOINT 열에 /가 있는 파티션을 보는 대신 두 번째 드라이브의 마운트 포인트가 무엇이든 있는 파티션을 찾으세요.
해당 파티션과 연결된 디스크로 두 번째 쿼리 필드를 업데이트합니다.
Disk Temp
이것은 운영 체제 디스크의 현재 온도를 추적합니다. 단계는 위의 CPU Temp 상자와 동일하므로 이 상자에 대해서도 해당 지침을 따르되 CPU 칩 및 센서 값을 운영 체제 디스크의 값으로 대체합니다. 이러한 값을 첫 번째 쿼리 필드에 채웁니다.
선택적으로 시스템의 두 번째 디스크의 현재 온도도 추적할 수 있습니다. 동일한 프로세스를 따라 설정하되 칩 및 센서 값을 두 번째 드라이브의 값으로 대체합니다. 이러한 값을 두 번째 쿼리 필드에 채웁니다.
대시보드 사용자 지정
표준 대시보드가 한눈에 보고 싶은 모든 것을 캡처하려고 시도하지만 원하는 대로 Grafana 대시보드를 사용자 지정하는 것은 매우 쉽습니다.
새 그래프를 추가하고, 그래프 모양을 변경하고, 항목을 이동하는 등의 작업을 할 수 있습니다!
Grafana의 Tutorials 페이지를 살펴보고 어떻게 사용하고 원하는 대로 설정하는지 알아보세요.
메트릭 스택 사용자 지정
Rocket Pool 메트릭 스택에 사용되는 도구는 기본 Rocket Pool 설치에 포함된 것 이상의 광범위한 구성 옵션을 제공합니다. 이 섹션에는 다양한 사용 사례에 대한 구성 예가 포함되어 있습니다.
일반적으로 Grafana 구성 옵션은 override/grafana.yml의 환경 변수를 사용하여 전달해야 합니다. 모든 구성 옵션은 다음 구문을 사용하여 환경 변수로 변환할 수 있습니다:
GF_<SectionName>_<KeyName>
이메일 전송을 위한 Grafana SMTP 설정
Grafana에서 이메일을 보내려면(예: 알림 또는 다른 사용자를 초대하기 위해) Rocket Pool 메트릭 스택에서 SMTP 설정을 구성해야 합니다.
참조를 위해 Grafana SMTP 구성 페이지를 참조하세요.
텍스트 편집기에서 ~/.rocketpool/override/grafana.yml을 엽니다.
x-rp-comment: Add your customizations below this line 줄 아래에 environment 섹션을 추가하고 아래 값을 SMTP 공급자의 값으로 대체합니다.
version: "3.7"
services:
grafana:
x-rp-comment: Add your customizations below this line
environment:
## SMTP settings start, replace values with those of your SMTP provider
- GF_SMTP_ENABLED=true
- GF_SMTP_HOST=mail.example.com:`port` # Gmail users should use smtp.gmail.com:587
- GF_SMTP_USER=admin@example.com
- GF_SMTP_PASSWORD=password
- GF_SMTP_FROM_ADDRESS=admin@example.com
- GF_SMTP_FROM_NAME="Rocketpool Grafana Admin"
## SMTP server settings end
텍스트 편집기에서 /etc/grafana/grafana.ini를 엽니다. [smtp] 섹션을 찾아 업데이트하고 아래 값을 SMTP 공급자의 값으로 대체합니다.
[smtp]
enabled = true
host = mail.example.com:`port` # Gmail users should use smtp.gmail.com:587
user = admin@example.com
# If the password contains # or ; you have to wrap it with triple quotes. Ex """#password;"""
password = """passw0rd"""
from_address = admin@example.com
from_name = "Rocketpool Grafana Admin"
이러한 수정을 한 후 다음을 실행하여 변경 사항을 적용합니다:
docker stop rocketpool_grafana
rocketpool service start
sudo systemctl restart grafana-server
SMTP 설정을 테스트하려면 Alerting 메뉴로 이동하여 Contact points를 클릭합니다.
New contact point를 클릭하고 Contact point type으로 Email을 선택합니다.
Addresses 섹션에 이메일 주소를 입력하고 Test를 클릭합니다.
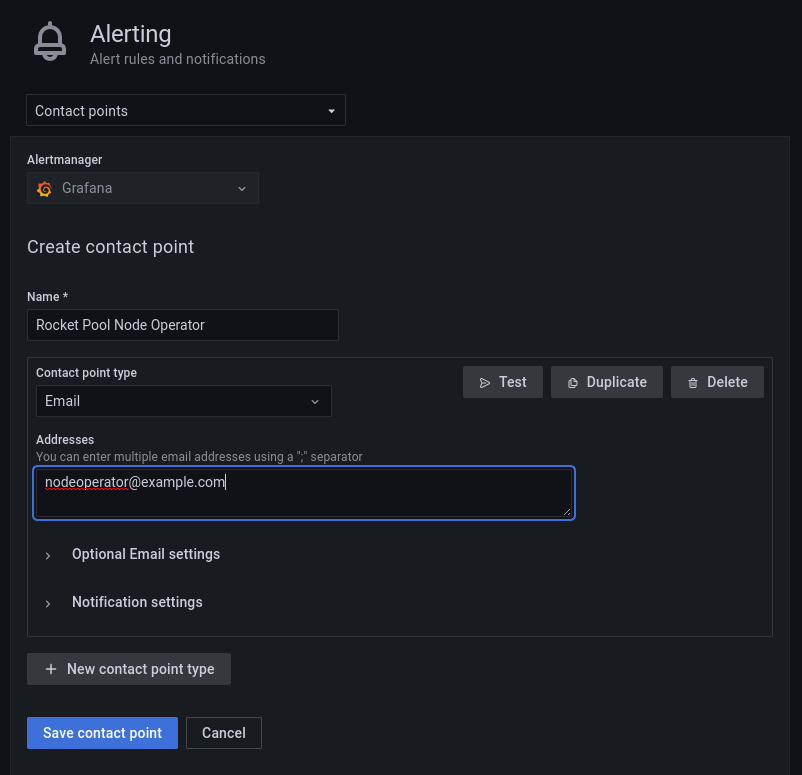
테스트 이메일이 수신되었는지 확인합니다.
완료되면 Save contact point*를 클릭합니다.