Grafanaダッシュボードの設定
ノードが稼働したら、すべてが正常に機能しているか(そしてどのような収益を生み出しているか)を一目で監視できる便利な方法が欲しくなるでしょう。
これを実現するツールは数多く存在します。
最も人気のあるツールの1つがGrafanaです。ブラウザでアクセスできる使いやすい汎用ダッシュボードシステムです。
Rocket PoolはGrafanaとその依存関係をすぐに使えるようにサポートしており、各Consensusクライアント用に事前構築されたダッシュボードも付属しています。
例えば、Hoodiテストネットワークのダッシュボードのスナップショットは次のようになります。
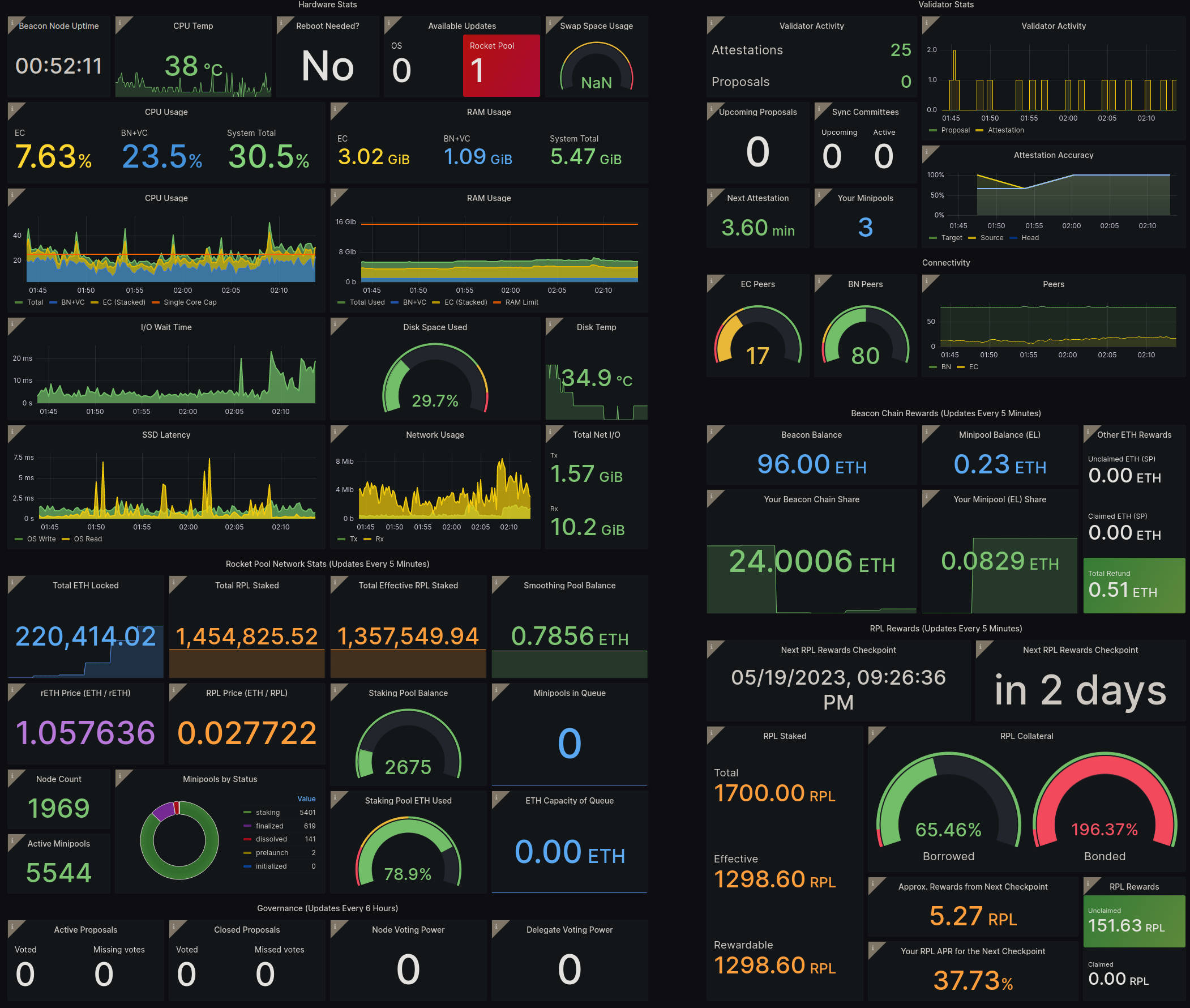
標準ダッシュボードには、次の情報が便利な形式で含まれています。
- 左上: マシンの健全性とパフォーマンスに関する重要な統計情報、および保留中のシステムアップデート
- 右上: Beacon Chain上のvalidatorのアクティビティとパフォーマンス、ExecutionおよびConsensusクライアントの統計情報
- 左下: 参考のためのRocket Poolネットワーク全体の詳細
- 右下: ETHとRPLの両方のstaking報酬の詳細
このガイドでは、Rocket Poolのメトリクスシステムを有効にして、このダッシュボードを使用する方法(または独自のダッシュボードを構築する方法)を説明します。
Rocket Pool Metricsスタックの概要
Smartnode設定プロセス中にメトリクスを有効にすることを選択すると、ノードに次のプロセスが追加されます。
- Prometheus - 上記のすべてのメトリクス(およびさらに多くのメトリクス)を収集、保存、レポートするデータ収集・保存・レポートシステムで、時間経過とともに確認できるように保存します
- Prometheus Node Exporter - マシンの健全性に関する情報(CPU使用率、RAM使用率、空きディスク容量とスワップ領域など)を収集し、Prometheusに報告するサービス
- Grafana、ノードでホストされている便利なウェブサイトを通じてPrometheusのデータを公開するツール
- 利用可能なOSアップデートをPrometheusに報告するオプションのカスタムスクリプトセット。システムにパッチが必要かどうかを確認できます
デフォルト設定では、Smartnodeの他のDockerコンテナと並んで存在するこれらすべてのサービスを含むDockerコンテナが作成されます。
Grafana用にノードマシンでポートが開かれるため、ローカルネットワーク上のブラウザを使用して任意のマシンからダッシュボードにアクセスできます。
Metricsサーバーの有効化
Dockerモードでメトリクスを有効にするのが最も簡単です。
まず、Smartnode設定コマンドを再度実行します。
rocketpool service config
Monitoring / Metricsセクションに移動し、Enable Metricsチェックボックスをオンにします。
ポート設定を細かく調整したい場合は、ここで行うことができます。
これらのポートはすべて、Grafanaポートを除いてDockerの内部ネットワークに制限されていることに注意してください。Grafanaポートはマシンで開かれます(デスクトップや携帯電話などの他のマシンからブラウザ経由でアクセスできるようにするため)。デフォルトのポートが既存のものと競合する場合は変更することをお勧めします。
保存して終了すると、smartnodeがPrometheus、Node Exporter、GrafanaのDockerコンテナを起動します。
ConsensusクライアントとValidatorクライアントも変更され、独自のメトリクスをPrometheusに公開するようになります。
OSとRocket Poolアップデートトラッカーは、最大限の柔軟性のためにデフォルトではインストールされませんが、プロセスは簡単です。
ダッシュボードにシステムで利用可能なアップデート数を表示したい場合は、次のコマンドでインストールできます。
rocketpool service install-update-tracker
内部的には、これによりOSのパッケージマネージャーにフックするサービスがインストールされ、定期的にアップデートをチェックし、その情報をPrometheusに送信します。
このサービスはOSごとに異なりますが、次のOSで動作することが確認されています。
- Ubuntu 20.04+
- Debian 9 and 10
- CentOS 7 and 8
- Fedora 34
注意
サービスの自動有効化はSELinuxと互換性がありません。
システムでSELinuxがデフォルトで有効になっている場合(CentOSやFedoraの場合)、インストールコマンドは_ほとんどの作業を完了_しますが、最後に手動でプロセスを完了する方法の指示も提供されます。
このチェック中に、インストールされているRocket Pool Smartnodeバージョンと最新リリースも比較し、新しいリリースが利用可能な場合は通知します。
アップデートトラッカーを有効にした場合、最後のステップは次のコマンドでNode Exporterを再起動することです。
docker restart rocketpool_exporter
その後、すべての設定が完了します。
HybridモードはDockerモードと同様に機能します。唯一の違いは、ExecutionおよびConsensusクライアントサービス定義に、メトリクスを有効にするための適切なコマンドラインフラグを手動で追加する必要があることです。
まず、Executionクライアントを更新します。
Executionクライアントのインストール時に作成したsystemdユニットファイルを開き、実行しているクライアントに基づいて正しいフラグがあることを確認します。
--metrics --metrics.addr 0.0.0.0 --metrics.port 9105
--Metrics.Enabled true --Metrics.ExposePort 9105
--metrics-enabled --metrics-host=0.0.0.0 --metrics-port=9105
次に、Consensusクライアントを更新します。
Consensusクライアントのインストール時に作成したsystemdユニットファイルを開き、実行しているクライアントに基づいて正しいフラグがあることを確認します。
--metrics --metrics-address 0.0.0.0 --metrics-port 9100 --validator-monitor-auto
--metrics --metrics.address 0.0.0.0 --metrics.port 9100
--metrics --metrics-address=0.0.0.0 --metrics-port=9100
--monitoring-host 0.0.0.0 --monitoring-port 9100
--disable-monitoringフラグがある場合は削除してください。
--metrics-enabled=true --metrics-interface=0.0.0.0 --metrics-port=9100 --metrics-host-allowlist=*
これらのフラグが既に設定されていて、ソロvalidator監視用に異なるポートを使用している場合は、そのままにして、使用しているポートをメモしてください。
次に、上にスクロールしてこのセクションのDockerタブの指示に従ってプロセスを完了します。rocketpool service configを実行する際に、使用しているカスタムポートで記載されているポートを置き換える必要があることに注意してください。
GrafanaとPrometheusのNativeインストールは、上級ユーザーのみにお勧めします。systemd、ファイル権限、ユーザー、ネットワーク管理などのLinux管理スキルが必要です。
まず、ExecutionクライアントとConsensusクライアントでメトリクスが有効になっていることを確認します。詳細については、「Hybrid」タブを参照してください。
次に、公式ダウンロードページでprometheusとnode_exporterの事前ビルドパッケージを確認します。
プラットフォームに適したアーキテクチャ(amd64またはarm64)のパッケージを選択してください。
最新のLTS(Long Time Support)バージョンのPrometheusをお勧めします。
例えば、wgetを使用してLinux amd64用のprometheus v2.45.3 LTSとnode_exporter v1.7.0をダウンロードするには、次のようにします。
wget https://github.com/prometheus/prometheus/releases/download/v2.45.3/prometheus-2.45.3.linux-amd64.tar.gz
wget https://github.com/prometheus/node_exporter/releases/download/v1.7.0/node_exporter-1.7.0.linux-amd64.tar.gz
wget https://github.com/prometheus/alertmanager/releases/download/v0.26.0/alertmanager-0.26.0.linux-amd64.tar.gz
ダウンロードしたアーカイブからprometheusとnode_exporterの実行ファイルを抽出します。
sudo tar -zxvf prometheus-2.45.3.linux-amd64.tar.gz -C /usr/local/bin --wildcards '*/prometheus' --strip-components=1
sudo tar -zxvf node_exporter-1.7.0.linux-amd64.tar.gz -C /usr/local/bin --wildcards '*/node_exporter' --strip-components=1
sudo tar -zxvf alertmanager-0.26.0.linux-amd64.tar.gz -C /usr/local/bin --wildcards '*/alertmanager' --strip-components=1
prometheusとalertmanagerの設定用ディレクトリを作成します。
sudo mkdir /etc/prometheus
sudo mkdir /etc/alertmanager
sudo mkdir /var/lib/prometheus
sudo mkdir /var/lib/alertmanager
次の内容で/etc/prometheus/prometheus.ymlファイルを作成します。
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
scrape_timeout: 12s # Timeout must be shorter than the interval
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9091"]
- job_name: "node"
static_configs:
- targets: ["localhost:9103"]
# - targets: ['localhost:9103', 'node_hostname:9103']
- job_name: "eth1"
static_configs:
- targets: ["localhost:9105"]
# Uncomment the line below if you are using geth as Execution Client
#metrics_path: /debug/metrics/prometheus
- job_name: "eth2"
static_configs:
- targets: ["localhost:9100"]
- job_name: "validator"
static_configs:
- targets: ["validator:9101"]
- job_name: "rocketpool"
scrape_interval: 5m
scrape_timeout: 5m
static_configs:
- targets: ["node:9102"]
- job_name: "watchtower"
scrape_interval: 5m
scrape_timeout: 5m
static_configs:
- targets: ["watchtower:9104"]
alerting:
alertmanagers:
- static_configs:
- targets: ["localhost:9093"]
注意
必要に応じて、ExecutionクライアントとConsensusクライアントのポート番号を変更してください。
prometheus変更を実行しているホストとは異なるホストでノードを実行している場合があります。その場合は、
rocketpoolノードホストにnode_exporterをインストールし、監視するすべてのマシンを含めるようにnodeジョブのtargetsを更新してください。
Executionクライアントがgethの場合は、metrics_pathも調整してください。gethはメトリクス用に非標準のエンドポイントを公開します。
次の内容で/etc/alertmanager/alertmanager.ymlを作成します。
global:
# ResolveTimeout is the default value used by alertmanager if the alert does
# not include EndsAt, after this time passes it can declare the alert as resolved if it has not been updated.
# This has no impact on alerts from Prometheus, as they always include EndsAt.
# default = 5m
resolve_timeout: 5m
route:
# The labels by which incoming alerts are grouped together.
group_by: ["alertname"]
# How long to initially wait to send a notification for a group
# of alerts. Allows to wait for an inhibiting alert to arrive or collect
# more initial alerts for the same group.
group_wait: 30s
# How long to wait before sending a notification about new alerts that
# are added to a group of alerts for which an initial notification has
# already been sent. (Usually ~5m or more.)
group_interval: 5m
# How long to wait before sending a notification again if it has already been sent successfully for an alert.
repeat_interval: 4h
routes:
# severity=info: Don't send the follow-up resolved notification.
- match:
severity: info
continue: false
# The notification destination
receiver: "node_operator_no_resolved"
# all other alerts get sent notifications for the initial firing _and_ resolved notifications.
- receiver: "node_operator_default"
#match: We want this to match all alerts (severity=info is first though so it will stop)
# The notification destination
receiver: "node_operator_default"
receivers:
- name: "node_operator_default"
discord_configs:
- webhook_url: "https://discord.com/api/webhooks/1206697259694170212/_Pk1eVVgXFLdwU1k0rfwehSvNLiAQJytVV_Ze8QYOhupHnhiB5c8awPBTfuw41lN9GJk"
- name: "node_operator_no_resolved"
discord_configs:
- webhook_url: "https://discord.com/api/webhooks/1206697259694170212/_Pk1eVVgXFLdwU1k0rfwehSvNLiAQJytVV_Ze8QYOhupHnhiB5c8awPBTfuw41lN9GJk"
send_resolved: false
inhibit_rules:
# Inhibit rules mute a new alert (target) that matches an existing alert (source).
- source_match:
# if the existing alert (source) is severity=critical
severity: "critical"
target_match:
# and the new alert (target) is severity=warning
severity: "warning"
# and the alertname, job, and instance labels have the same value
equal: ["alertname", "job", "instance"]
prometheusとalertmanager用のシステムユーザーを作成します。
sudo useradd -r -s /sbin/nologin prometheus
sudo useradd -r -s /sbin/nologin alertmanager
prometheusとalertmanagerファイルの所有権と権限を変更します。
sudo chown prometheus:prometheus /usr/local/bin/prometheus
sudo chown alertmanager:alertmanager /usr/local/bin/alertmanager
sudo chown prometheus:prometheus /usr/local/bin/node_exporter
sudo chown -R prometheus:prometheus /etc/prometheus
sudo chown -R alertmanager:alertmanager /etc/alertmanager
sudo chown -R prometheus:prometheus /var/lib/prometheus
sudo chown -R alertmanager:alertmanager /var/lib/alertmanager
sudo chmod u+sx,g+sx,o-wx /usr/local/bin/prometheus
sudo chmod u+sx,g+sx,o-wx /usr/local/bin/alertmanager
sudo chmod u+sx,g+sx,o-wx /usr/local/bin/node_exporter
node_exporterサービス設定用に/lib/systemd/system/node-exporter.serviceファイルを作成します。
[Unit]
Description=Node metrics exporter for Prometheus
Documentation=https://prometheus.io/docs/introduction/overview
Wants=network-online.target
After=network-online.target
[Service]
User=prometheus
Group=prometheus
Type=simple
Restart=on-failure
WorkingDirectory=/var/lib/prometheus
RuntimeDirectory=node-exporter
RuntimeDirectoryMode=0750
ExecStart=/usr/local/bin/node_exporter --web.listen-address=:9103
[Install]
WantedBy=multi-user.target
注意
node_exporterが実行されているポートを変更したい場合は、
ExecStartパラメータのコマンドを変更してください。デフォルトポートは9100です。
prometheusサービス設定用に/lib/systemd/system/prometheus.serviceファイルを作成します。
[Unit]
Description=Prometheus instance
Documentation=https://prometheus.io/docs/introduction/overview
Wants=network-online.target
After=network-online.target
[Service]
User=prometheus
Group=prometheus
Type=simple
Restart=on-failure
WorkingDirectory=/var/lib/prometheus
RuntimeDirectory=prometheus
RuntimeDirectoryMode=0750
ExecStart=/usr/local/bin/prometheus --config.file /etc/prometheus/prometheus.yml --web.listen-address=:9091
[Install]
WantedBy=multi-user.target
注意
prometheusが実行されているポートを変更したい場合は、
ExecStartパラメータのコマンドを変更してください。デフォルトポートは9090です。
alertmanagerサービス設定用に/lib/systemd/system/alertmanager.serviceファイルを作成します。
[Unit]
Description=Alertmanager instance
Documentation=https://prometheus.io/docs/alerting/latest/alertmanager/
Wants=network-online.target
After=network-online.target
[Service]
User=alertmanager
Group=alertmanager
Type=simple
Restart=on-failure
WorkingDirectory=/var/lib/alertmanager
RuntimeDirectory=alertmanager
RuntimeDirectoryMode=0750
ExecStart=/usr/local/bin/alertmanager --config.file /etc/alertmanager/alertmanager.yml --web.listen-address=:9093
[Install]
WantedBy=multi-user.target
注意
alertmanagerが実行されているポートを変更したい場合は、
ExecStartパラメータのコマンドを変更してください。デフォルトポートは9093です。
新しいサービスについてsystemdに通知します。
sudo systemctl daemon-reload
node-exporterサービスを有効にして起動します。
sudo systemctl enable node-exporter
sudo systemctl start node-exporter
サービスのステータスを確認して、実行中であることを確認します。
sudo systemctl status node-exporter
prometheusサービスを有効にして起動します。
sudo systemctl enable prometheus
sudo systemctl start prometheus
alertmanagerサービスを有効にして起動します。
sudo systemctl enable alertmanager
sudo systemctl start alertmanager
サービスのステータスを確認して、実行中であることを確認します。
sudo systemctl status prometheus
sudo systemctl status alertmanager
Grafana用のパッケージリポジトリをセットアップします。
sudo apt-get update
sudo apt-get install -y apt-transport-https software-properties-common
sudo mkdir -p /etc/apt/keyrings/
wget -q -O - https://apt.grafana.com/gpg.key | gpg --dearmor | sudo tee /etc/apt/keyrings/grafana.gpg > /dev/null
echo "deb [signed-by=/etc/apt/keyrings/grafana.gpg] https://apt.grafana.com stable main" | sudo tee -a /etc/apt/sources.list.d/grafana.list
Grafanaをインストールします。
sudo apt-get update
sudo apt-get install grafana
/etc/grafana/grafana.iniの設定を確認します。このドキュメントの他のセクションに合わせて、http_portを3100に変更します。
GrafanaでPrometheusからメトリクスを視覚化するためのデータソースを設定します。/etc/grafana/provisioning/datasources/prometheus.ymlファイルを作成します。
apiVersion: 1
deleteDatasources:
- name: Prometheus
orgId: 1
datasources:
- name: Prometheus
type: prometheus
access: proxy
orgId: 1
url: http://localhost:9091
basicAuth: false
isDefault: true
version: 1
editable: true
注意
Prometheusのリスニングポートを変更した場合は、
urlを編集してください。
Grafana用のサービスを有効にして起動します。
sudo systemctl daemon-reload
sudo systemctl enable grafana-server
sudo systemctl start grafana-server
Grafanaが起動して実行中であることを確認します。
sudo systemctl status grafana-server
これで完了です。
監視用の接続を許可するようにファイアウォールを設定する
注意
Securing your Nodeセクションで参照されているようにUFWを有効にしている場合、PrometheusとExecution/Consensusクライアント間のローカル接続を許可するために、いくつかのポートを開く必要があります。以下の手順に従ってください。
次のコマンドを実行し、必要に応じてポートを置き換えます。
RP_NET=$(docker inspect rocketpool_net | grep -Po "(?<=\"Subnet\": \")[0-9./]+")
sudo ufw allow from $RP_NET to any port 9105 comment "Allow Prometheus access to Execution Client"
sudo ufw allow from $RP_NET to any port 9100 comment "Allow Prometheus access to Consensus Client"
sudo ufw allow from $RP_NET to any port 9103 comment "Allow Prometheus access to Exporter"
RocketPoolノードとPrometheusが異なるホストにある場合、PrometheusホストIPからノード監視ポートへの着信トラフィックを許可するように、ノードホストでファイアウォールを設定する必要があります。
また、PrometheusホストからRocketPoolノードホストへの発信トラフィックを許可するように、PrometheusマシンでUFWを設定する必要があります。
ノードホストIPが192.168.1.5でPrometheusホストIPが192.168.1.6の場合、ノードのUFWルールは次のようになります。
sudo ufw allow from 192.168.1.6 to any port 9100:9105 proto tcp comment 'Allow Prometheus host to scrape metrics of this host'
Prometheusホストの場合:
sudo ufw allow out from any to 192.168.1.5 port 9100:9105 proto tcp comment 'Allow this host to scrape node metrics'
Grafanaリスニングポートが3100であると仮定して、読み進めてネットワークでGrafanaを公開する方法を確認してください。
その後、ファイアウォールを開いて、外部デバイスがGrafanaダッシュボードにアクセスできるようにすることができます。
ローカルネットワーク内の任意のマシンからGrafanaにアクセスできるようにし、他のすべての場所からのアクセスを拒否する場合は、これを使用します。
これが最も一般的な使用例です。
まず、ローカルネットワークが192.168.1.xxx構造を使用しているかどうかを確認してください。
異なるアドレス構造(例: 192.168.99.xxx)を使用している場合は、ローカルネットワークの構成に合わせて以下のコマンドを変更する必要がある場合があります。
# This assumes your local IP structure is 192.168.1.xxx
sudo ufw allow from 192.168.1.0/24 proto tcp to any port 3100 comment 'Allow grafana from local network'
Rocket Poolノードが、Grafanaを表示するデバイスと同じサブネットに接続されていない場合は、これを使用します。これは、ノードがISPのモデムに直接接続されており、Grafanaを表示するために使用するデバイスがセカンダリルーターに接続されている場合に発生する可能性があります。
まず、ローカルネットワークが192.168.1.xxx構造を使用しているかどうかを確認してください。
異なるアドレス構造(例: 192.168.99.xxx)を使用している場合は、ローカルネットワークの構成に合わせて以下のコマンドを変更する必要がある場合があります。
# To allow any devices in the broader subnet
# for example allowing 192.168.2.20 to access
# grafana on 192.168.1.20
sudo ufw allow from 192.168.1.0/16 proto tcp to any port 3100 comment 'Allow grafana from local subnets'
これにより、どこからでもGrafanaにアクセスできるようになります。
ローカルネットワークの外部からアクセスする場合は、ルーター設定でGrafanaポート(デフォルト3100)を転送する必要があります。
# Allow any IP to connect to Grafana
sudo ufw allow 3100/tcp comment 'Allow grafana from anywhere'
Grafanaのセットアップ
これでメトリクスサーバーの準備が整いました。ローカルネットワーク上の任意のブラウザでアクセスできます。
Smartnodeインストールモードについては、以下のタブを参照してください。
次のURLに移動し、必要に応じて変数をセットアップに置き換えます。
http://<your node IP>:<grafana port>
例えば、ノードのIPが192.168.1.5で、デフォルトのGrafanaポート3100を使用した場合、ブラウザで次のURLにアクセスします。
次のようなログイン画面が表示されます。

デフォルトのGrafana情報は次のとおりです。
Username: admin
Password: admin
その後、adminアカウントのデフォルトパスワードを変更するように求められます。
強力なパスワードを選択し、忘れないようにしてください。
ヒント
adminパスワードを紛失した場合は、ノードで次のコマンドを使用してリセットできます。
docker exec -it rocketpool_grafana grafana-cli admin reset-admin-password admin
sudo grafana-cli admin reset-admin-password admin
デフォルトのadmin認証情報を使用してGrafanaに再度ログインでき、その後adminアカウントのパスワードを変更するように求められます。
コミュニティメンバーのtedsteenの功績により、GrafanaはPrometheusインスタンスに自動的に接続されるため、収集したメトリクスにアクセスできます。
あとはダッシュボードを取得するだけです。
Rocket Poolダッシュボードのインポート
GrafanaをPrometheusに接続したので、標準ダッシュボードをインポートできます(または、そのプロセスに精通している場合は、提供されるメトリクスを使用して独自のダッシュボードを構築できます)。
まず、Createメニュー(右側のバーのプラスアイコン)に移動し、Importをクリックします。
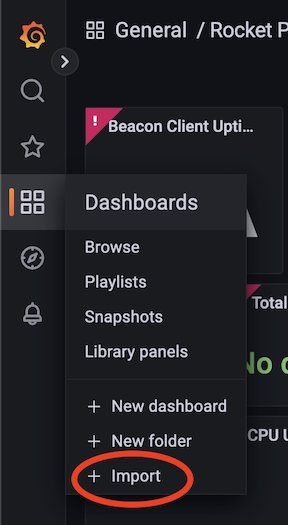
Import via grafana.comボックスでダッシュボードIDの入力を求められたら、21863を入力するか、完全なURL((https://grafana.com/grafana/dashboards/24900-rocket-pool-dashboard-v1-4-0/)を使用して、Loadボタンを押します。
ダッシュボードに関する情報(名前や保存場所など)が表示されます(デフォルトのGeneralフォルダで問題ありません。多くのダッシュボードを使用していて整理したい場合を除きます)。
下部のPrometheusドロップダウンには、**Prometheus (default)**というラベルの付いた単一のオプションのみが表示されるはずです。
このオプションを選択します。
画面は次のようになります。
一致する場合は、Importボタンをクリックすると、新しいダッシュボードにすぐに移動します。
一見すると、ノードとvalidatorに関する多くの情報が表示されます。
各ボックスには、左上隅に便利なツールチップ(iアイコン)が付いており、マウスを合わせると詳細を確認できます。
例えば、Your Validator Shareボックスのツールチップは次のとおりです。
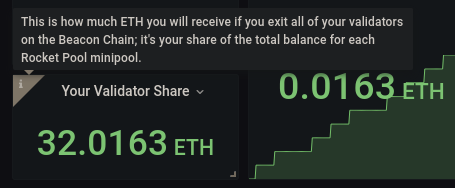
ただし、設定はまだ完了していません。まだもう少し設定が必要です。
注意
一部のボックス(特にAPRのボックス)は、Shapellaがスキムされた報酬を提供する方法により、一時的に無効になっています。
過去の報酬を適切に追跡できるSmartnodeの将来のバージョンで再び有効になります。
システムに合わせてハードウェアモニターを調整する
ダッシュボードが起動したので、SSD LatencyやNetwork Usageなどのいくつかのボックスが空であることに気付くかもしれません。
これらをキャプチャする方法を認識できるように、特定のハードウェアに合わせてダッシュボードを調整する必要があります。
CPU Temp
CPU温度ゲージを更新するには、CPU Tempボックスのタイトルをクリックし、ドロップダウンからEditを選択します。
画面は次のようになります。
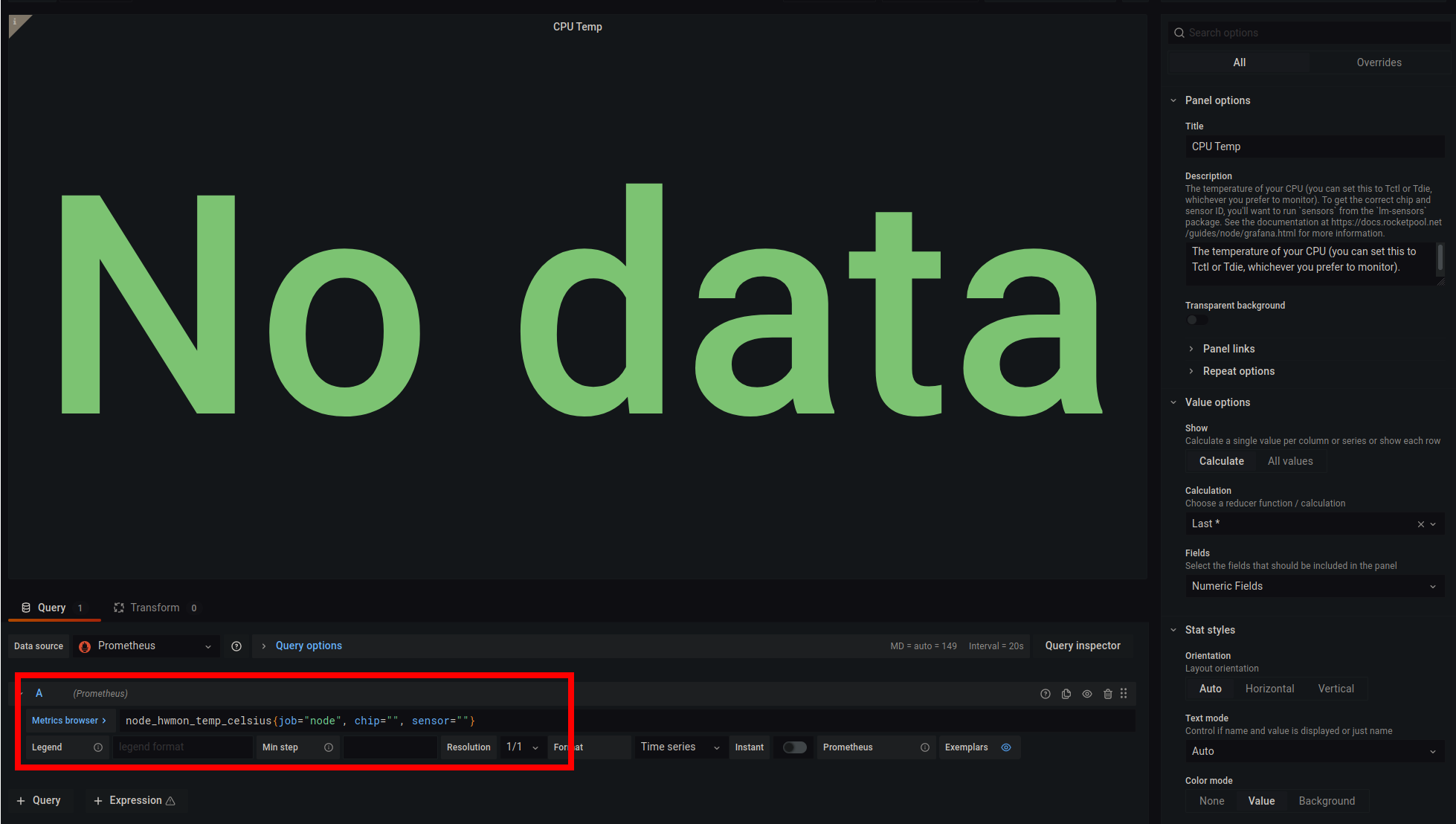
これはGrafanaの編集モードです。表示される内容と見た目を変更できます。
Metrics browserボタンの右側にある、赤で強調表示されたクエリボックスに注目しています。
デフォルトでは、そのボックスには次のようなものがあります。
node_hwmon_temp_celsius{job="node", chip="", sensor=""}
このテキストには現在空白の2つのフィールドがあります: chipとsensor。
これらは各マシンに固有であるため、マシンが提供するものに基づいて入力する必要があります。
これを行うには、次の手順に従います。
, sensor=""の部分を削除して、chip=""}で終わるようにします。明確にするために、全体はnode_hwmon_temp_celsius{job="node", chip=""}になります。chip=""の引用符の間にカーソルを置き、Ctrl+Spacebarを押します。これにより、利用可能なオプションが表示された自動補完ボックスが表示されます。次のようになります。
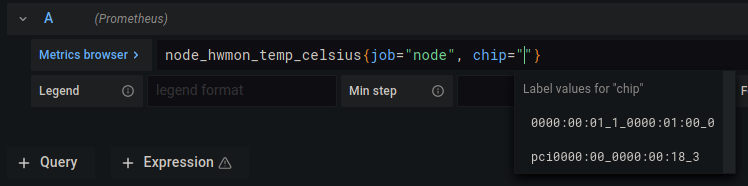
- システムのCPUに対応するオプションを選択します。
- それが選択されたら、
, sensor=""を文字列に戻します。sensor=""の引用符の間にカーソルを置き、Ctrl+Spacebarを押して別の自動補完メニューを表示します。監視するセンサーを選択します。
ヒント
どのchipまたはsensorが正しいかわからない場合は、正しく見えるものが見つかるまですべてを試す必要があります。これを支援するには、lm-sensorsパッケージをインストールし(例: Debian/Ubuntuではsudo apt install lm-sensors)、sensors -uコマンドを実行して、コンピュータが持っているセンサーを提供します。名前とIDに基づいて、GrafanaのリストからチップIDをここで表示されるものと関連付けることができます。
例えば、これはsensors -uコマンドの出力の1つです。
k10temp-pci-00c3
Tctl:
temp1_input: 33.500
Tdie:
temp2_input: 33.500
この場合、Grafanaの対応するチップはpci0000:00_0000:00:18_3で、対応するセンサーはtemp1です。
選択に満足したら、画面の右上隅にある青いApplyボタンをクリックして設定を保存します。
注意
すべてのシステムがCPU温度情報を公開するわけではありません。特に仮想マシンやクラウドベースのシステムです。
chipの自動補完フィールドに何もない場合は、おそらくこれが原因であり、CPU温度を監視できません。
SSD Latency
SSD Latencyチャートは、読み取り/書き込み操作にかかる時間を追跡します。
これは、validatorのパフォーマンスが低下した場合に、SSDがボトルネックになっているかどうかを判断するのに役立ちます。
チャートで追跡するSSDを更新するには、SSD LatencyタイトルをクリックしてEditを選択します。
このチャートには、合計8つのdevice=""部分を持つ4つのクエリフィールド(4つのテキストボックス)があります。
追跡するデバイスで、これらの部分の最初の4つを更新する必要があります。
引用符の間にカーソルを置き、Ctrl+Spacebarを押してGrafanaの自動補完リストを表示し、各device=""部分の正しいオプションを選択します。
一番左の空の設定から始める必要があります。そうしないと、自動補完リストが表示されない場合があります。
ヒント
追跡するデバイスがわからない場合は、次のコマンドを実行します。
これにより、デバイスとパーティションリストを示すツリーが出力されます。例えば:
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
...
loop25 7:25 0 132K 1 loop /snap/gtk2-common-themes/9
loop26 7:26 0 65,1M 1 loop /snap/gtk-common-themes/1515
nvme0n1 259:0 0 238,5G 0 disk
├─nvme0n1p1 259:1 0 512M 0 part /boot/efi
├─nvme0n1p2 259:2 0 150,1G 0 part /
├─nvme0n1p3 259:3 0 87,4G 0 part
└─nvme0n1p4 259:4 0 527M 0 part
Smartnodeインストール中にDockerのデフォルトの場所を別のドライブに変更しなかった場合、追跡するディスクはOSがインストールされているディスクになります。
MOUNTPOINT列で単に/とラベル付けされたエントリを探し、それを親デバイス(TYPE列にdiskがあるもの)まで遡ります。
通常、SATAドライブの場合はsda、NVMeドライブの場合はnvme0n1になります。
Dockerのデフォルトの場所を別のドライブに変更した場合、またはhybrid/nativeセットアップを実行している場合は、「マウントポイントを辿る」という同じ手法を使用して、チェーンデータが存在するデバイスを決定できるはずです。
オプションで、システム上の2番目のディスクのレイテンシを追跡することもできます。
これは、OSとチェーンデータを別々のドライブに保存している人を対象としています。
これを設定するには、上記の指示に従って最後の2つのクエリフィールドを設定し、device=""部分の値を追跡するディスクの値に置き換えます。
選択に満足したら、画面の右上隅にある青いApplyボタンをクリックして設定を保存します。
Network Usage
このチャートは、特定のネットワーク接続を介して送受信しているデータ量を追跡します。
ご想像のとおり、ダッシュボードは追跡するネットワークを知る必要があります。
変更するには、Network UsageタイトルをクリックしてEditを選択します。
このチャートには、合計2つのdevice=""部分を持つ2つのクエリフィールドがあります。
追跡するネットワークでこれらを更新する必要があります。
引用符の間にカーソルを置き、Ctrl+Spacebarを押してGrafanaの自動補完リストを表示し、各device=""部分の正しいオプションを選択します。
ヒント
追跡するデバイスがわからない場合は、次のコマンドを実行します。
出力は次のようになります。
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
default 192.168.1.1 0.0.0.0 UG 100 0 0 eth0
192.168.1.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
192.168.1.1 0.0.0.0 255.255.255.255 UH 100 0 0 eth0
Destination列で値がdefaultの行を探します。
その行をIface列まで辿ります。
そこにリストされているデバイスが使用するものです。この例ではeth0です。
選択に満足したら、画面の右上隅にある青いApplyボタンをクリックして設定を保存します。
Total Net I/O
これは、送受信したデータの総量を追跡します。
例えば、ISPが月ごとに特定の量のデータに制限している場合に便利です。
設定は上記のNetwork Usageボックスと同じであるため、このボックスについても同じ指示に従ってください。
Disk Space Used
これは、OSディスクがどれだけいっぱいになっているかを追跡するため、クリーンアップする時期(そしてチェーンデータが同じドライブにある場合は、GethまたはNethermindをプルーニングする時期)がわかります。
手順は上記のSSD Latencyボックスと同じであるため、このボックスについても同じ指示に従ってください。
念のため、これについてはOSドライブになるため、MOUNTPOINT列に/があるパーティションを収容するドライブが必要です。
これを最初のクエリフィールドに入力します。
オプションで、システム上の2番目のディスクの空き容量を追跡することもできます。
これは、OSとチェーンデータを別々のドライブに保存している人を対象としています。
同じプロセスに従ってこれを設定しますが、MOUNTPOINT列に/があるパーティションを見る代わりに、2番目のドライブのマウントポイントがあるパーティションを探します。
そのパーティションに関連付けられたディスクで2番目のクエリフィールドを更新します。
Disk Temp
これは、OSディスクの現在の温度を追跡します。手順は上記のCPU Tempボックスと同じであるため、このボックスについても同じ指示に従い、CPUチップとセンサーの値をOSディスクの値に置き換えます。これらの値を最初のクエリフィールドに入力します。
オプションで、システム上の2番目のディスクの現在の温度を追跡することもできます。同じプロセスに従ってこれを設定し、チップとセンサーの値を2番目のドライブの値に置き換えます。これらの値を2番目のクエリフィールドに入力します。
ダッシュボードのカスタマイズ
標準ダッシュボードは、一目で見たいすべてのものをキャプチャするのに適していますが、Grafanaダッシュボードは好きなようにカスタマイズするのは非常に簡単です。
新しいグラフを追加したり、グラフの見た目を変更したり、物を移動したりすることができます。
Grafanaのチュートリアルページを見て、操作方法や好みに合わせて設定する方法を学んでください。
Metricsスタックのカスタマイズ
Rocket Pool Metricsスタックで使用されるツールは、デフォルトのRocket Poolインストールに含まれているもの以外にも、さまざまな設定オプションを提供します。このセクションには、さまざまなユースケースの設定例が含まれています。
一般的に、Grafana設定オプションは、override/grafana.ymlで環境変数を使用して渡す必要があります。すべての設定オプションは、次の構文を使用して環境変数に変換できます。
GF_<SectionName>_<KeyName>
メール送信用のGrafana SMTP設定
Grafanaからメールを送信するには、例えばアラートや他のユーザーを招待するために、Rocket Pool MetricsスタックでSMTP設定を構成する必要があります。
参考としてGrafana SMTP構成ページを参照してください。
テキストエディタで~/.rocketpool/override/grafana.ymlを開きます。
x-rp-comment: Add your customizations below this line行の下にenvironmentセクションを追加し、以下の値をSMTPプロバイダーの値に置き換えます。
version: "3.7"
services:
grafana:
x-rp-comment: Add your customizations below this line
environment:
## SMTP settings start, replace values with those of your SMTP provider
- GF_SMTP_ENABLED=true
- GF_SMTP_HOST=mail.example.com:`port` # Gmail users should use smtp.gmail.com:587
- GF_SMTP_USER=admin@example.com
- GF_SMTP_PASSWORD=password
- GF_SMTP_FROM_ADDRESS=admin@example.com
- GF_SMTP_FROM_NAME="Rocketpool Grafana Admin"
## SMTP server settings end
テキストエディタで/etc/grafana/grafana.iniを開きます。[smtp]セクションを探して更新し、以下の値をSMTPプロバイダーの値に置き換えます。
[smtp]
enabled = true
host = mail.example.com:`port` # Gmail users should use smtp.gmail.com:587
user = admin@example.com
# If the password contains # or ; you have to wrap it with triple quotes. Ex """#password;"""
password = """passw0rd"""
from_address = admin@example.com
from_name = "Rocketpool Grafana Admin"
これらの変更を行った後、次のコマンドを実行して変更を適用します。
docker stop rocketpool_grafana
rocketpool service start
sudo systemctl restart grafana-server
SMTP設定をテストするには、Alertingメニューに移動してContact pointsをクリックします。
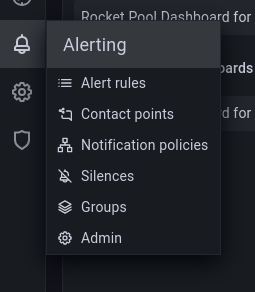
New contact pointをクリックし、Contact point typeとしてEmailを選択します。
Addressesセクションにメールアドレスを入力し、Testをクリックします。
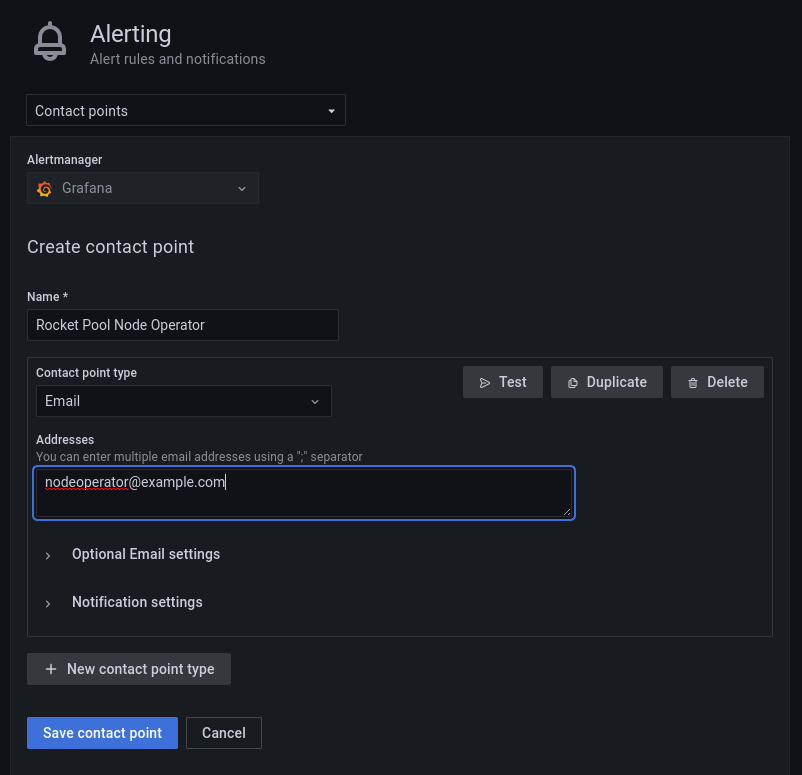
テストメールが受信されたことを確認します。
完了したらSave contact point*をクリックします。